Osnova sekcie
-
-
Test slúžiaci na zhodnotenie získaných znalostí po absolvovaní všetkých tém Spúšťanie úloh na vysokovýkonnom klastri.
-
Cieľ: Cieľom témy Úvod je uviesť účastníka kurzu do problematiky a aktuálnosti používania počítačových klastrov
Prerekvezity: žiadne
Počítačový klaster
Pod pojmom klaster rozumieme zhluk viacerých vzájomne prepojených počítačov. Takéto riešenie potrebuje vhodný komunikačný mechanizmus medzi jednotlivými procesormi. Jedným z najvhodnejších riešení pre tento typ systému je zasielanie správ. So zvyšujúcimi sa nárokmi na čas potrebný pre vykonanie zložitých úloh, bol prechod od sekvenčného programovania k paralelnému nevyhnutný. Neexistuje, a je nemožné, vyrobiť a efektívne používať procesor s potrebnou taktovacou frekvenciou pre dnešné zložité vedecké úlohy. To je dôvod pre použitie viac procesorov a paralelne písané programy. klaster zostavení z niekoľkých procesorov, s ktorým program pracuje ako s multiprocesorovým systémom s distribuovanou alebo zdieľanou pamäťou. Aktuálny zoznam najvýkonnejších svetových superpočítačov je možné nájsť na http://www.top500.org/lists/ .
Ďalšími typmi vysokovýkonného počítania, ktoré vychádzajú zo základu počítačového klastra sú grid computing a cloud computing. Pri grid computingu sú pospájané viaceré klastre do jedného systému, ktoré sú rôzne geograficky umiestnené. Cloud computing poskytuje počítačové zdroje bez fyzického prístupu dostupné cez internet.
História a súčasnosť
V histórii vývoja vysoko výkonného počítania, s takými vlastnosťami a možnosťami ako ich poznáme dnes, malo zásadný vplyv vznikanie a vylepšovania ostatných technológii a služieb v počítačovom svete. Vývoj začal prvou generáciou počítačov a pokračuje dodnes štvrtou generáciou mikroprocesorov. Postupom času vznikol nový pojem klaster. Rovnako, ako sa prepojenie počítačov a komunikácia medzi nimi neskončila len v používaní terminálov a malých lokálnych sietí ale vyvinula sa celosvetová počítačová sieť internet, tak nastala „evolúcia“ aj vo využívaní počítačových zdrojov, ktoré máme k dispozícii. Potreba zvýšenia efektívnosti využívania týchto zdrojov je v dôsledku optimalizácie nákladov, zlepšenia služieb alebo dosiahnutia vysokého výpočtového výkonu. Okrem vývoja architektúry počítačov, počítačových sietí, operačných systémov bola dôležitá aj virtualizácia a vývoj softvéru.
K prvým "vysoko výkonným" klastrom môžeme prirovnať veľké sálové počítače dostupné pre organizácie a podniky v 50. rokoch dvadsiateho storočia. Počítače boli zoskupené do veľkých rozmerov v jednej alebo viacerých miestnostiach, ktoré sa dajú nazvať prvými serverovňami. Hlavné využitie bolo pre štatistické účely, finančné operácie ale aj na spracovanie veľkého objemu dát. Náklady na kúpu a správu sálových počítačov v tomto období boli značné a organizácie nemohli zabezpečiť toto riešenie pre každého používateľa, ktorý vyžadoval dostatočne vysoký výkon. Riešením bolo používanie terminálov s minimálnym výkonom, ktoré umožnilo pomocou príkazov prístup skupine viacerých používateľov, ktorí tak mohli využívať rovnaké spoločné dátové úložisku a výkon.
Významným prínosom použitia počítačových zdrojov, či už vo forme lokálnych klastrov, grid computingu alebo cloud computingu, je tiež využitie na vedecké účely, kde sa vyžaduje vysoký výpočtový výkon. Výsledkom sú zložité chemické, biologické, matematické a iné simulácie. Najčastejšie môžu ľudia využiť tieto výhody z vedeckých účelov napr. aj vo forme predpovede počasia, na ktorej majú spomenuté technológie podstatný podiel.
Vysoko výkonné počítanie na UMB
Spúšťanie úloh pre vysoko výkonné počítanie prebieha na klastri FPV, ktorý pozostáva z celkových 49 fyzických serverov. Tieto fyzické servery majú dokopy 560 jadier s podporou technológie spoločnosti Intel pre multiprocesorové operácie - Hyper Threading. Zároveň klaster FPV obsahuje 8 grafických akcelerátorov nVidia Tesla.

Počítačový klaster FPV UMB
Univerzita Mateja Bela je zapojená v národnom projekte štrukturálnych fondov Slovenská infraštruktúra pre vysokovýkonné počítanie (SIVVP), ktorého cieľom je vytvorenie slovenskej gridovej a superpočítačovej infraštruktúry, v rámci ktorej boli vybudované špecializované strediská disponujúce modernou vysokovýkonnou výpočtovou technikou, superpočítačmi a vysokokapacitnými úložiskami dát vo vybraných pracoviskách univerzít a SAV. Správu klastra zabezpečuje Centrum pre vysokovýkonné počítanie (High Performance Computig Center - HPCC UMB), ktoré vzniklo pre tento účel 1. 6. 2012. Hlavným cieľom tohto pracoviska je poskytovať služby vedcom, ktorí vo svojich výskumoch potrebujú realizovať výpočty na infraštruktúre SIVVP. Klaster na UMB zapojený aj do európskej gridovej infraštruktúry (EGI), čo ponúka používateľom ďalšie možnosti a prístup k ďalším zdrojom.
Aktivity: 0 -
Cieľ: Cieľom témy Hardvérový (HW) opis je priblížiť používateľovi dostupné a používané architektúry pre počítačové klastre
Prerekvezity: žiadne
Metódy programovania
Paralelné výpočty sú postupným vývojom od sekvenčných výpočtov, ktorý sa snaží napodobniť stav podobnému ako vo svete okolo nás. Mnoho zložitých a vzájomne prepojených udalostí sa deje v rovnakú dobu ale v poradí. Dôvod na prechod k paralelným výpočtom bola narastajúca zložitosť programov na procesor. Vyskytol sa problém z časového hľadiska a výkonových požiadaviek na systém. Princíp sekvenčného programovania je, že sa vykonáva jedna úloha a ostatné čakajú kým sa spracuje predošlá. Je nemožné donekonečna zvyšovať výkon počítača len pomocou jediného procesora. Takýto procesor by spotreboval neakceptovateľne veľa energie.

Sekvenčné programovanieViacjadrové procesory svojím príchodom rozšírili spôsob dovtedy málo používanej paralelizácia. Vykonávané úlohy sa síce nespracúvajú na niekoľkých procesoroch ale len jadrách. To nám neprinesie najvyšší možný výkon ale výhodou je, že komunikácia medzi jadrami je rýchlejšia ako medzi procesormi. Pre dosiahnutie naozaj veľkého výkonu je omnoho praktickejšie používať veľa takýchto jednoduchých procesorov pre dosiahnutie požadovaného výkonu, aj keby sme ich mali použiť tisíce.
Pri náročných programoch prichádza k zbytočnému časovému zdržaniu, ktoré sa dá odstrániť práve paralelným programovaním a výpočtami. Paralelné výpočty môžu mať algoritmus, kde vzťahy medzi premennými sú závislé alebo nezávislé. V každom prípade tu je priestor pre urýchlenie algoritmu a to tak, že niektoré čiastkové úlohy programu môžu bežať práve súbežne pri zachovaní funkčnosti a správnosti program. Paralelizácia teda znamená rozdelenie úlohy na komponenty, ktoré prebiehajú simultánne na viacerých procesoroch komunikujúcich prostredníctvom nejakej siete, zbernice.

Paralelné programovanie
Optimálny výkon počítača pre paralelné výpočty je závislý od každej úrovne: algoritmu, operačného systému, kompilátora a samozrejme hardvéru.
Flynnova taxonómia
Multiprocesorový systém alebo multipočítač je zložený z niekoľkých klasických procesorov. Algoritmy a multiprocesorové architektúry sú úzko zviazané dohromady. Nemôžeme rozmýšľať nad paralelnými algoritmami, bez toho, aby sme rozmýšľali nad ich využitím paralelným hardvérom, ktorý ich bude podporovať. Naopak, nemôžeme premýšľať nad využitím paralelného hardvéru bez myslenia na softvér, ktorý ho bude riadiť.
Paralelizmus tak môže byť realizovaný vo výpočtovom systéme na rôznych úrovniach pomocou hardvérového a softvérového riešenia, napríklad dátový, inštrukčný, vláknový a procesový paralelizmus. Existujú rôzne možnosti návrhov, ktoré máme dispozícii pri stavbe paralelného počítačového systému.
Najznámejšia procesorová taxonómia bola navrhnutá Flynnom (americký profesor zo Stanfordskej Univerzity) a bola založená na dátach a vykonávaných operáciách na týchto dátach:
- SISD – prípad systému s jedným procesorom
- SIMD – všetky procesory vykonajú rovnaký zoznam inštrukcií na rôznych dátach. Každý procesor má vlastné dáta v lokálnej pamäti a procesory si vymieňajú dáta medzi sebou obvykle cez jednoduchú komunikačnú schému. Príkladom využitia SIMD je grafické spracovanie, video kompresia atď.
- MISD – všetky procesory vykonávajú rôzne inštrukcie na rovnakých dátach
- MIMD –
každý procesor vykonáva svoje vlastné inštrukcie na vlastných lokálnych dátach.
Príkladom sú multiprocesorové a multipočítačové systémy.
Bežne najviac používané paralelné počítačové architektúry sú: multiprocesory so zdieľanou pamäťou, multiprocesory s distribuovanou pamäťou, SIMD procesory, klastrové počítanie, cloudové (gridové) počítanie a viacjadrové procesory.
Pamäťové architektúry
Poznáme tri základné rozdelenia podľa pamäťovej architektúry: zdieľaná, distribuovaná a hybridná pamäť.
Pri architektúre zdieľanej pamäte, každý procesor obsiahnutý v systéme zdieľa tie isté pamäťové prostriedky, pričom pracuje samostatne. Pamäť tvorí jeden globálny pamäťový priestor, do ktorého má prístup každý procesor. Zdieľanú pamäť môžeme rozdeliť ešte do dvoch podskupín podľa času prístupu do pamäte:
- jednotný čas prístupu (Uniform Memory Access)

UMA- nerovnomerný čas prístupu (Non-Uniform Memory Access)

NUMA
Výhodami pri systéme so zdieľanou pamäťou sú ľahšie programovateľné kvôli globálnemu adresnému priestoru a z dôvodu tesného prepojenia pamäte s procesormi rýchle zdieľanie dát. Nevýhodami tohto riešeniami sú slabá škálovateľnosť a zodpovedajúce zabezpečenie synchronizácie pre správny prístup do globálnej pamäte.
V multiprocesorovom systéme s distribuovanou pamäťou je pamäťový modul spojený s procesorom, takže každý procesor môže pristupovať k svojej vlastnej pamäti a na prepojenie medziprocesorovej pamäte je potrebná komunikačná sieť. V tomto riešení pamäťovej architektúry neexistuje žiaden spoločný globálny pamäťový priestor a zmeny v lokálnej pamäti nemajú žiaden vplyv na pamäť ostatných procesorov.

Zdieľaná pamäť
Pri práci s takýmto typom systému sa používa mechanizmus zasielania správ s cieľom umožniť prístup procesoru k ďalším pamäťovým modulom v kombinácii s inými procesormi. Multiprocesorový systém s distribuovanou pamäťou sa môže skladať z homogénnych procesorov, takže sa jedná o symetrický viacprocesorový systém. Asymetrický viacprocesorový systém sa skladá z viacerých heterogénnych procesorov.
Hybrid distribuovano-zdieľanej pamäte je používaný najväčšími a najvýkonnejšími superpočítačmi súčasnosti. Kombinuje metódy MPI a OpenMP. Pred 10 rokmi výnimočnosť a exotika, v blízkej budúcnosti bude tento spôsob pamäťovej architektúry v oblasti najnáročnejších výpočtov najpoužívanejší.

Hybrid distribuovano-zdieľanej pamäte
Aktivity: 0 -
Cieľ: Téma Dostupný softvér a kompilátory má za cieľ oboznámiť používateľa o softvérových a vývojových prostrediach na počítačovom klastri
Prerekvezity: Hardvérový (HW) opis
Softvér
Kto sa už stretol s používaním operačného systému Linux, konkrétne cez konzolu, nebude mať problém zvyknúť si na prostredie, lebo pre počítačový klaster FPV sa používa linuxová distribúcia Scientific Linux. Táto distribúcia, spoluvyvýjaná aj s organizáciou CERN, optimalizuje využívanie dostupného výpočtového výkonu pre výpočty, pričom obmedzuje "plytvanie" výkonu na užívateľské prostredie. Momentálne dostupný softvér pre používanie používateľmi zasahuje do oblastí matematiky, informatiky, chémie a aj fyziky.
Komerčným, ale aj voľne dostupným softvérom pre prácu, prevádzkovaným na klastri FPV, sú Matlab (s množstvom rôznych toolboxov), Mathematica, Gaussian09, CRYSTAL09, OCTAVE, MOLCAS a aj Dirac.
Kompilátory
Z dostupných kompilátorov sú pre potreby používateľov dostupné Intel® Fortran Professional Edition For Linux, Intel® C++ Compiler Professional Edition For Linux, PGI® C, C++ & Fortran Compilers & Tools For Multi-core x64+GPU Workstations and Clusters.
Aktivity: 0 -
Goal: Goal of this topic Methodology of work on computer cluster is to acquaint user with process operations which are needed for successful work on this cluster
Prerequisites: Available software and compilators
Process operations
Running tasks successfully on the computer claster of FPV needed to follow some process operations. These operations are:
- Perform user verification with generating new own private key to login on the cluster
- Create user account by administrator
- Prepare and transfer startup script and program on the cluster
- Successful login on the cluster
- Compile and run startup script
Aktivity: 0 -
Goal: Goal of User verification topic is to gain practice and theoretic knowledges for getting access on the cluster
Prerequisites: Methodology of work on computer cluster
How to get access
The prerequisite for that we can run tasks on high performance cluster, it is necessary to ensure the identification of user who wants to use it. Verification is via using SSH keys. To create these keys we use free program for key generation PuTTYgen on Windows. Private keys using this program must be converted to a format .ppk. During key generation in the environment program, you must enter your own secret passphrase. Result are two keys - public and private. The public key must be provided to the system administrator, send to mail address Jozef.Silaci@umb.sk and private key left user for himself and not send it further.
Generovanie kľúčov
- Z internetovej stránky http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html si stiahnite voľne dostupný program PuTTygen
- Pretože nie je vyžadovaná inštalácia, program môžete rovno spustiť
- V okne hlavného programu kliknite na Generate
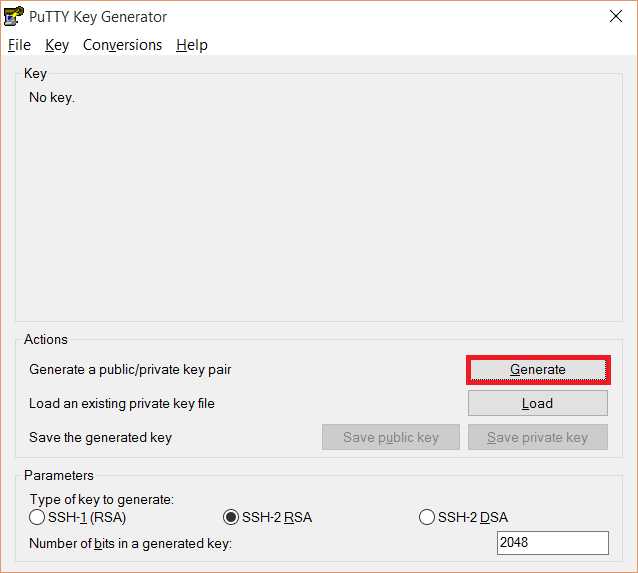
Tlačidlo pre generovanie kľúčov
- Pre vygenerovanie kľúčov je potrebné aby ste dostatočne pohybovali kurzorom myši vo zvýraznenej ploche. Týmto spôsobom sa získavajú náhodné dáta, ktoré budú následne použité pre samotné generovanie
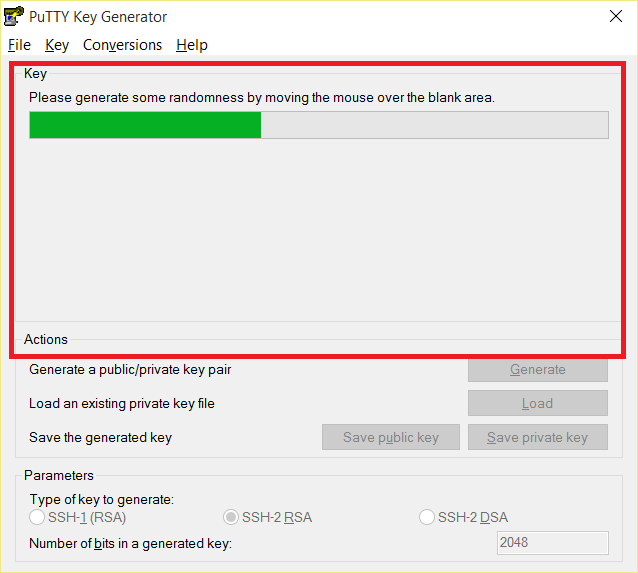
Priestor na pohyb kurzorom myši V nasledujúcom kroku je možné priradiť komentár pre vygenerované kľúče a nutné zadať passphrase, ktorá bude slúžiť ako heslo pri každom prihlásení sa s týmto kľúčom
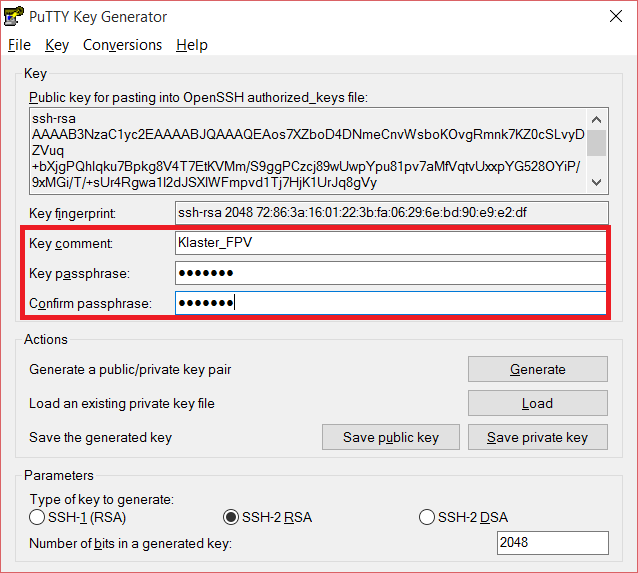
Zadávanie vlastností pre vygenerovaný kľúčTakto vygenerovaný pár kľúčov postupne uložíme ako public a private key
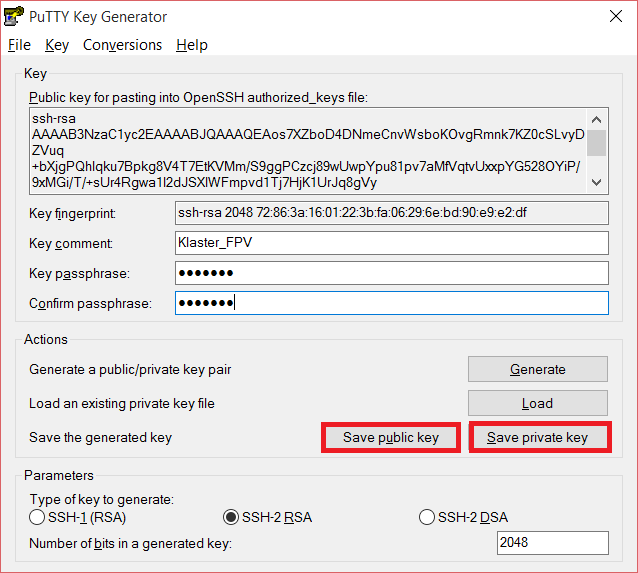
Uloženie páru vygenerovaných kľúčov
Videotutoriál je dostupný nižšie:
Aktivity: 0 -
Cieľ: V tejto téme budú objasnené princípy prenosu súborov na klaster a následné prihlásenie sa na naň
Prerekvezity: Overenie totožnosti používateľa
Prenos súborov
Po vygenerovaní SSH kľúčov, poslaní potrebného verejného kľúča administrátorovi systému a vytvorením konta z jeho strany, sme pripravení sa pripojiť na systém počítačového klastra FPV. Spôsob pripojenia je rozdielny na rôznych operačných systémoch. V tejto téme sa budeme špeciálne venovať dvom operačným systémom a to Linux a Windows.Linux
V prípade Linuxu sa prihlasujeme prostredníctvom terminálu. Postup je nasledovný:
- V Termináli zadáme príkaz na inštaláciu openssh, ktorý umožňuje prenos súborov na vzdialený server nasledovne:
sudo apt-get install openssh
- Teraz zadáme príkaz na prenos súboru:
scp -i <cesta_kde_je_umiestneny_privatny_kluc> <cesta_ku_suboru_ktory_sa_ma_preniest> <pouzivatelske_meno_od_adminsitratora>@194.160.44.230:/home/
Windows
Pre operačný systém Microsoft Windows je postup na prenesenie súborov nasledovný:
- Zo stránky https://winscp.net/eng/download.php stiahnuť voľne dostupný program WinSCP
- Spustiť program a nastaviť takto:
- File protocol: SCP
- Host name: 194.160.44.230
- Port number: 22
- User name: podľa pridelenia od administrátora klastra
- Teraz kliknúť na Advanced, v ponuke na ľavej strane prejsť na SSH->Authentication a vybrať cestu k privátnemu kľúču pre Private key file, potvrdiť OK
- Teraz kliknúť na Login a po vyzvaní zadať passphrase, ktorú sme si nastavili pri generovaní privátneho kľúča v program PuTTYgen
- Súbor môžeme skopírovať do adresára /home pretiahnutím alebo vybraním a skopírovaním z adresárovej štruktúry
Prihlásenie sa na klaster
Po úspešnom prenesení požadovaných súborov na klaster sa prihlásime naň prihlásime cez ssh. Znova je viac spôsobov ako toto prihlásenie vykonať, ktoré záleží od použitého operačného systému. Tak ako v predošlej kapitole bude postup znázornení na operačnom systéme Linux a Microsoft.
Linux
Pre operačný systém Linux je postup prihlásenia sa na klaster nasledovný:
- V Termináli zadáme príkaz pre ssh pripojenie:
ssh -i <cesta_kde_je_umiestneny_privatny_kluc> <pouzivatelske_meno_od_adminsitratora>@194.160.44.230
Windows
Prihlásenie sa na klaster v operačnom systéme Windows použijeme voľne dostupný program PuTTY. Postupujeme takto:
- Z adresy http://www.chiark.greenend.org.uk/~sgtatham/putty/download.html stiahneme a spustíme program PuTTY
- Nastavíme Host Name na adresu 194.160.44.230
- V ľavej časti programu prejdeme v strome na Connection->SSH->Auth a vyberieme cestu k privátnemu kľúču pre Private key file for authentication, potvrdíme kliknutím na Open
- Po otvorení nového okna a vyzvaní zadáme:
- login as: <používateĺské meno získané od administrátora>
- Passphrase for key: <passphrasa, ktorú sme zadali pri vytváraní konkrétneho privátneho kľúča>
Videotutoriál pre prenos súborov - Windows:
Videotutoriál pre prihlásenie sa na klaster - Windows:
Aktivity: 0 - V Termináli zadáme príkaz na inštaláciu openssh, ktorý umožňuje prenos súborov na vzdialený server nasledovne:
-
Cieľ: Téma Kompilácia a lokálne spustenie programu objasňuje postup pre úspešné spustenie požadovaného programu
Prerekvezity: Prenos súborov a prihlásenie sa na klaster
Kompilácia programu
Program môžeme skompilovať zadaním príkazu rôznymi spôsobmi podľa použitého jazyka, samozrejme, musíme ho mať prenesený na klaster:
- C:
gcc <nazov_kompilovaneho_programu> -o <nazov_programu_po_skompilovani>
- C pri viacerých zdrojových súboroch
make <nazov_kompilovaneho_programu>
- C pri použití metódy zasielania správ MPI
mpicc -o <nazov_programu_po_skompilovani> <nazov_kompilovaneho_programu>
- C++
g++ <nazov_kompilovaneho_programu> -o <nazov_programu_po_skompilovani>
- C++ pri viacerých zdrojových súboroch
make <nazov_kompilovaneho_programu>
- C++ pri použití metódy zasielania správ MPI
mpic++ -o <nazov_programu_po_skompilovani> <nazov_kompilovaneho_programu>
Lokálne spustenie programu
Program môžeme lokálne spustiť zadaním príkazu rôznymi spôsobmi podľa použitého jazyka, samozrejme, musíme ho mať úspešne skompilovaní:
- C, C++
./<nazov_programu>
- C, C++ s použitím metódy zasielania správ MPI
mpirun -np <poćet_procesov> <názov_programu>
Aktivity: 0 - C:
-
Cieľ: Cieľom témy je získať poznatky ako úspešne spustiť predpripravený spúšťací skript
Prerekvezity: Kompilácia a spustenie programu
PBS súbor
Ak chceme spustiť úlohu v prostredí vysoko výkonného klastra, budeme musieť nastaviť dávkový súbor Portable Batch System (PBS). Súbor PBS definuje príkazy a prostriedky klastra používané na prácu. Tento PBS súbor je jednoduchý textový súbor, ktorý je možné ľahko upravovať pomocou editora, akým je napríklad Vi. Môže byť ľubovoľne pomenovaný, preto skripty s názvom napr. myscript.job, myscript.pbs alebo myscript pracujú rovnako správne.
Spúšťací skript je jednoduchý shell skript. Skladá sa zo smerníc PBS, komentárov a vykonateľných príkazov. Znak # označuje koment, ale keď riadky začínajú s #PBS tak sú interpretované ako príkaz PBS. Prázdne riadky môžu byť zahrnuté pre lepšiu prehľadnosť.
Potvrdenie úlohy na spustenie
Po prihlásení na vysoko výkonný klaster je potrebné potvrdiť PBS job pre spustenie nami požadovanej úlohy. K tomu sa používa príkaz qsub, ktorý pošle úlohu do fronty PBS a požaduje dodatočné výpočtové zdroje. Príkaz qstat sa používa na kontrolu stavu úlohy už vo fronte PBS. Pre zjednodušenie potvrdenia úlohy vytvoríme skript PBS a použijeme príkazy qsub a qstat pre interakciu s frontou PBS.
Vytváranie PBS skriptu
Pre nastavenie potrebných parametrov pre našu prácu, môžeme vytvoriť ovládací súbor obsahujúci príkazy, ktoré majú byť vykonané. Zvyčajne je to vo forme skriptu PBS. Tento skript je potom potvrdený do fronty PBS pomocou príkazu qsub.
Nižšie je ukážkový PBS súbor s názvom my_job.sh a následné vysvetlenie každého riadku v súbore.#!/bin/bash ###Prvý riadok v súbore identifikuje, ktorý interpreter bude použitý pre úlohu #PBS -N dimacs_job ###Voliteľne môžeme pomenovať vykonávanú úlohu. Ak neposkytneme meno, bude použitý názov skriptu. Toto meno je súčasťou log súboru a taktiež sa zobrazí v zozname čakajúcich a spustených úloh. Môže byť dlhé až 15 znakov, bez medzier a začiatočný znak musí byť písmeno
#PBS -A cislo_projektu ###Spôsobuje, že čas potrebný na úlohu je daný k <account>, projektu. Číslo projektu je reťazec z troch písmen nasledovaných tromi číslicami, napr. edv001. Táto možnosť je vyžadovaná pre každú úlohu
#PBS -r n ###Deklaruje, či je úloha znovu spustiteľná. Môže mať parametre y pre áno a n pre nie #PBS -q batch ###Definuje cieľové umiestnenie pre úlohu. Môže obsahovať názov pre zoznam, server alebo zoznam na konkrétnom servery
#PBS -l nodes=1:ppn=32:ht ###Definuje požiadavky na zdroje pre vykonanie úlohy. Ak nie je zadané, zdroje sú používané bez obmedzenia. Tento konkrétny zápis vyžaduje jeden node a tridsaťdva virtuálnych procesorov pre node
#PBS -v tpt=1 ###Exportuje všetky premenné prostredia z potvrdzujúceho shellu do shellu vykonávača úloh. Neodporúča sa použiť bez vytvorenia potrebného prostredia medzi vykonávačom úlohy
#PBS -l mem=512mb ###Definuje maximálne požadované množstvo RAM pamäte pre vykonanie úlohy. Môže byť v kb pre kilobajty, mb pre magabajty alebo gb pre gigabajty
#PBS -l walltime=480:00:00 ###Maximálny skutočný čas, počas ktorého môže byť úloha v stave spustená. Udáva sa v HH:MM:SS
echo Working directory is $PBS_O_WORKDIR ###Výpis pracovného adresára cd $PBS_O_WORKDIR ###Zmenenie adresára na pracovný echo Running on host `hostname` ###Spúšťa dodatočné informácie echo Time is `date` echo Directory is `pwd` echo This jobs runs on the following processors: echo `cat $PBS_NODEFILE` NPROCS=`wc -l < $PBS_NODEFILE` ###Definuje počet procesorov echo This job has allocated $NPROCS cpus export SOFTDIR="/home/evesel/work" export Home=$PWD export Project=DSJC1000-5 export OMP_NUM_THREADS=16 export WorkDir=/mnt/local/$USER/$PBS_JOBID #----------------------------------------------------------------------------------------------------------------------# #rm -rf $WorkDir; mkdir -p $WorkDir; cd $WorkDir ${SOFTDIR}/pmc -a 0 -f $Home/$Project.mtx -t $OMP_NUM_THREADS > $Home/$Project.log #cd; rm -rf $WorkDir #----------------------------------------------------------------------------------------------------------------------#Spustenie úlohy
Po vytvorení a pripravení spúšťacieho skriptu, úlohu spustíme príkazom:
qsub <názov_spúštiaceho_skriptu>
Informácie o spustených úlohách získame príkazom:
qstatPotvrdenú úlohu zrušíme príkazom:
qdel <job_id>
Zdroj: https://www.osc.edu/supercomputing/batch-processing-at-osc/job-scripts
https://hpcc.usc.edu/support/documentation/running-a-job-on-the-hpcc-cluster-using-pbs/
Videotutoriál na spustenie úlohy:
Aktivity: 0 -
Cieľ: Téma Príklady má za cieľ ponúknuť praktické úlohy na ozrejmenie si doteraz získaných vedomostí ohľadom spúšťania úloh na vysokovýkonnom klastri
Prerekvezity: Spúšťací skript
Na vysoko výkonný klaster preneste svoju úlohu a podľa doteraz naštudovaných materiálov ju úspešne spustite.Úloha 1
Vykonajte spustenie nasledujúcej úlohy:
- RAM: 512 MB
- Počet nodov: 3
Úloha 2
Vykonajte spustenie nasledujúcej úlohy:
- RAM: 2018 MB
- Počet nodov: 1
- Procesy na node: 16
Prečo sa Úloha 2 nespustila v rozumnom čase?
Aktivity: 0